
Harnessing Multi-Core Power with Asyncio in Python
Boost your Python application’s performance by efficiently utilizing multiple CPU cores with asyncio


In this article, I will show you how to execute Python asyncio code on a multi-core CPU to unlock the full performance of concurrent tasks.
Introduction
What is our problem?
asyncio uses only one core.
In previous articles, I covered the mechanics of using Python asyncio in detail.
With this knowledge, you can learn that asyncio allows IO-bound tasks to execute at high speed by manually switching task execution to bypass the GIL contention process during multi-threaded task switching.
Theoretically, the execution time of IO-bound tasks depends on the time from initiation to the response of an IO operation and is not dependent on your CPU performance.
Thus, we can concurrently initiate tens of thousands of IO tasks and complete them quickly.
But recently, I was writing a program that needed to crawl tens of thousands of web pages simultaneously and found that although my asyncio program was much more efficient than programs that use iterative crawling of web pages, it still made me wait for a long time.
Should I be using the full performance of my computer? So I opened Task Manager and checked:
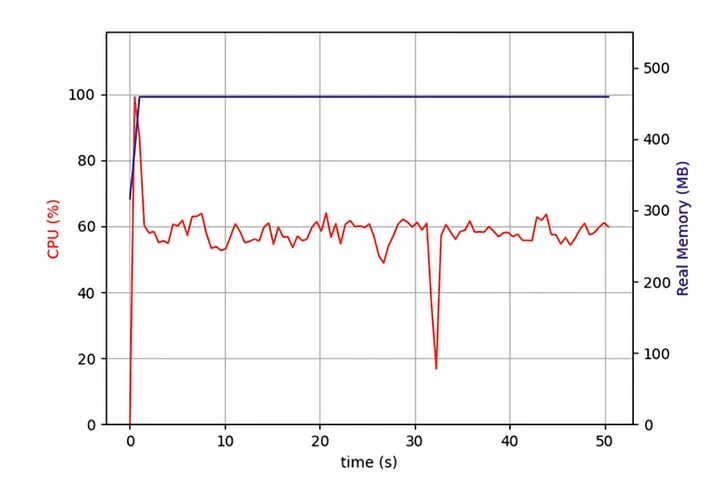
I found that since the beginning, my code was running on only one CPU core, and several other cores were idle. In addition to launching IO operations to grab network data, a task has to unpack and format the data after it returns.
Although this part of the operation does not consume much CPU performance, after more tasks, these CPU-bound operations will severely impact the overall performance.
I wanted to make my asyncio concurrent tasks execute in parallel on multiple cores. Would that squeeze the performance out of my computer?
The Underlying Principles of Asyncio
To solve this puzzle, we must start with the underlying asyncio implementation, the event loop.
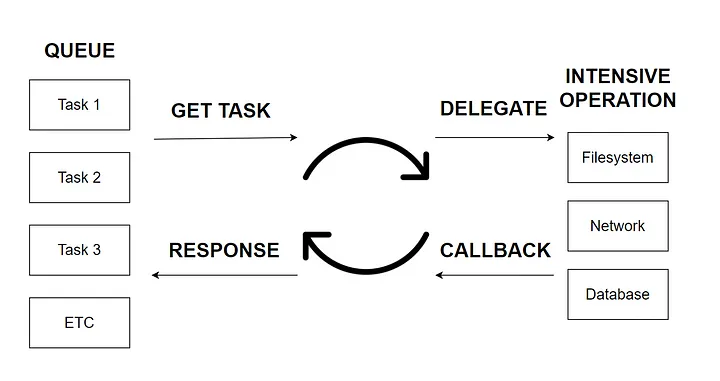
As shown in the figure, asyncio’s performance improvement for programs starts with IO-intensive tasks. IO-intensive tasks include HTTP requests, reading and writing files, accessing databases, etc.
The most important feature of these tasks is that the CPU does not block and spends a lot of time computing while waiting for external data to be returned, which is very different from another class of synchronous tasks that require the CPU to be occupied all the time to compute a specific result.
When we generate a batch of asyncio tasks, the code will first put these tasks into a queue.
At this point, there is a thread called event loop that grabs one task at a time from the queue and executes it.
When the task reaches the await statement and waits (usually for the return of a request), the event loop grabs another task from the queue and executes it.
Until the previously waiting task gets data through a callback, the event loop returns to the previous waiting task and finishes executing the rest of the code.
Since the event loop thread executes on only one core, the event loop blocks when the “rest of the code” happens to take up CPU time.
When the number of tasks in this category is large, each small blocking segment adds up and slows down the program as a whole.
What is My Solution
From this, we know that asyncio programs slow down because our Python code executes the event loop on only one core, and the processing of IO data causes the program to slow down.
Is there a way to start an event loop on each CPU core to execute it?
As we all know, starting with Python 3.7, all asyncio code is recommended to be executed using the method asyncio.run, which is a high-level abstraction that calls the event loop to execute the code as an alternative to the following code:
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()As you can see from the code, each time we call asyncio.run, we get (if it already exists) or create a new event loop.
Could we achieve our goal of executing asyncio tasks on multiple cores simultaneously if we could call the asyncio.run method on each core separately?
The previous article used a real-life example to explain using asyncio’s loop.run_in_executor method to parallelize the execution of code in a process pool while also getting the results of each child process from the main process.
If you haven’t read the previous article, you can check it out here:
 Peng Qian
Peng Qian
Thus, our solution emerges: distribute many concurrent tasks to multiple sub-processes using multi-core execution via the loop.run_in_executor method, and then call asyncio.run on each sub-process to start the respective event loop and execute the concurrent code.
The following diagram shows The entire flow:
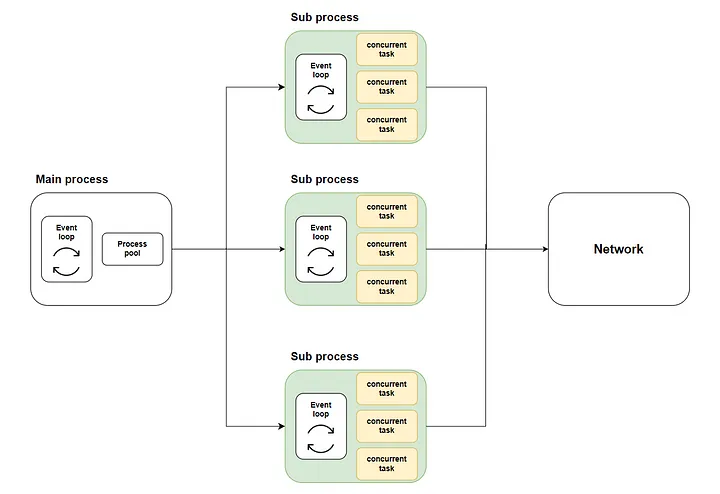
Where the green part represents the sub-processes we started. The yellow part represents the concurrent tasks we started.
Preparation Before Starting
Simulating the task implementation
Before we can solve the problem, we need to prepare before we start.
In this example, we can’t write actual code to crawl the web content because it would be very annoying for the target website, so we will simulate our real task with code:
async def fake_crawlers():
io_delay = round(random.uniform(0.2, 1.0), 2)
await asyncio.sleep(io_delay)
result = 0
for i in range(random.randint(100_000, 500_000)):
result += i
return resultAs the code shows, we first use asyncio.sleep to simulate the return of the IO task in random time and an iterative summation to simulate the CPU processing after the data is returned.
The effect of traditional code
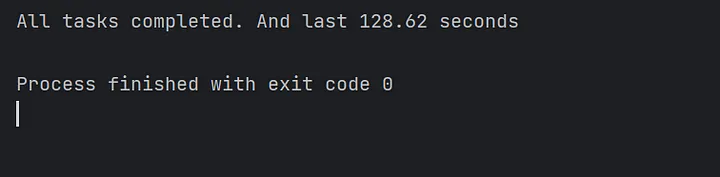
Next, we take the traditional approach of starting 10,000 concurrent tasks in a main method and watch the time consumed by this batch of concurrent tasks:
async def main():
start = time.monotonic()
tasks = [asyncio.create_task(fake_crawlers()) for i in range(10000)]
await asyncio.gather(*tasks)
print(f"All tasks completed. And last {time.monotonic() - start:.2f} seconds")As the figure shows, executing the asyncio tasks with only one core takes a longer time.
The Code Implementation
Next, let’s implement the multi-core asyncio code according to the flowchart and see if the performance is improved.
Designing the overall structure of the code
First, as an architect, we still need first to define the overall script structure, what methods are required, and what tasks each method needs to accomplish:
import asyncio
import time
from concurrent.futures import ProcessPoolExecutor
async def query_concurrently(begin_idx: int, end_idx: int):
""" Start concurrent tasks by start and end sequence number """
def run_batch_tasks(batch_idx: int, step: int):
""" Execute batch tasks in sub processes """
async def main():
""" Distribute tasks in batches to be executed in sub-processes """The specific implementation of each method
Then, let’s implement each method step by step.
The query_concurrently method will start the specified batch of tasks concurrently and get the results via the asyncio.gather method:
sync def query_concurrently(begin_idx: int, end_idx: int):
""" Start concurrent tasks by start and end sequence number """
tasks = []
for _ in range(begin_idx, end_idx, 1):
tasks.append(asyncio.create_task(fake_crawlers()))
results = await asyncio.gather(*tasks)
return resultsThe run_batch_tasks method is not an async method, as it is started directly in the child process:
def run_batch_tasks(batch_idx: int, step: int):
""" Execute batch tasks in sub processes """
begin = batch_idx * step + 1
end = begin + step
results = [result for result in asyncio.run(query_concurrently(begin, end))]
return resultsFinally, there is our main method. This method will call the loop.run_in_executor method to have the run_batch_tasks method execute in the process pool and merge the results of the child process execution into a list:
async def main():
""" Distribute tasks in batches to be executed in sub-processes """
start = time.monotonic()
loop = asyncio.get_running_loop()
with ProcessPoolExecutor() as executor:
tasks = [loop.run_in_executor(executor, run_batch_tasks, batch_idx, 2000)
for batch_idx in range(5)]
results = [result for sub_list in await asyncio.gather(*tasks) for result in sub_list]
print(f"We get {len(results)} results. All last {time.monotonic() - start:.2f} second(s)")Since we are writing a multi-process script, we need to use if __name__ == “__main__” to start the main method in the main process:
if __name__ == "__main__":
asyncio.run(main())Execute the code and see the results
Next, we start the script and look at the load on each core in the task manager:
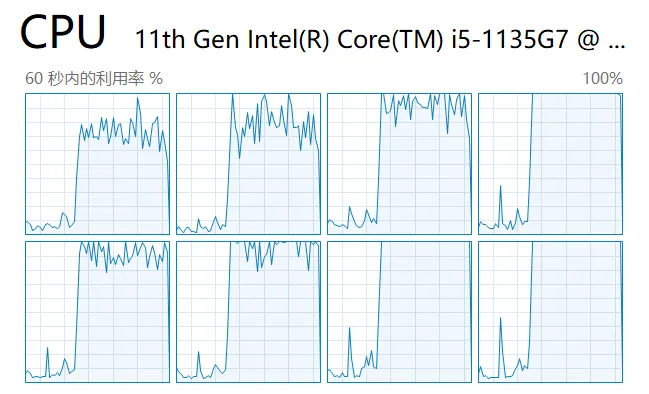
As you can see, all the CPU cores are utilized.
Finally, we observe the code execution time and confirm that the multi-threaded asyncio code does indeed speed up the code execution by several times! Mission accomplished!

Conclusion
In this article, I explained why asyncio could execute IO-intensive tasks concurrently but still takes longer than expected when running large batches of concurrent tasks.
It is because in the traditional implementation scheme of asyncio code, the event loop can only execute tasks on one core, and the other cores are in an idle state.
So I have implemented a solution for you to call each event loop on multiple cores separately to execute concurrent tasks in parallel. And finally, it improved the performance of the code significantly.
Due to the limitation of my ability, the solution in this article inevitably has imperfections. I welcome your comments and discussion. I will actively answer for you.



