
Introducing Python’s Parse: The Ultimate Alternative to Regular Expressions
Use best practices and real-world examples to demonstrate the powerful text parser library


This article introduces a Python library called parse for quickly and conveniently parsing and extracting data from text, serving as a great alternative to Python regular expressions.
And which covers the best practices with the parse library and a real-world example of parsing nginx log text.
Introduction
I have a colleague named Wang. One day, he came to me with a worried expression, saying he encountered a complex problem: his boss wanted him to analyze the server logs from the past month and provide statistics on visitor traffic.
I told him it was simple. Just use regular expressions. For example, to analyze nginx logs, use the following regular expression, and it’s elementary.
content:
192.168.0.2 - - [04/Jan/2019:16:06:38 +0800] "GET http://example.aliyundoc.com/_astats?application=&inf.name=eth0 HTTP/1.1" 200 273932
regular expression:
(?<ip>\d+\.\d+\.\d+\.\d+)( - - \[)(?<datetime>[\s\S]+)(?<t1>\][\s"]+)(?<request>[A-Z]+) (?<url>[\S]*) (?<protocol>[\S]+)["] (?<code>\d+) (?<sendbytes>\d+)But Wang was still worried, saying that learning regular expressions is too tricky. Although there are many ready-made examples online to learn from, he needs help with parsing uncommon text formats.
Moreover, even if he could solve the problem this time, what if his boss asked for changes in the parsing rules when he submitted the analysis? Wouldn’t he need to fumble around for a long time again?
Is there a simpler and more convenient method?
I thought about it and said, of course, there is. Let’s introduce our protagonist today: the Python parse library.
Installation & Setup
As described on the parse GitHub page, it uses Python’s format() syntax to parse text, essentially serving as a reverse operation of Python f-strings.
Before starting to use parse, let’s see how to install the library.
Direct installation with pip:
python -m pip install parseInstallation with conda can be more troublesome, as parse is not in the default conda channel and needs to be installed through conda-forge:
conda install -c conda-forge parseAfter installation, you can use from parse import * in your code to use the library’s methods directly.
Features & Usage
The parse API is similar to Python Regular Expressions, mainly consisting of the parse, search, and findall methods. Basic usage can be learned from the parse documentation.
Pattern format
The parse format is very similar to the Python format syntax. You can capture matched text using {} or {field_name}.
For example, in the following text, if I want to get the profile URL and username, I can write it like this:
content:
Hello everyone, my Medium profile url is https://qtalen.medium.com,
and my username is @qtalen.
parse pattern:
Hello everyone, my Medium profile url is {profile},
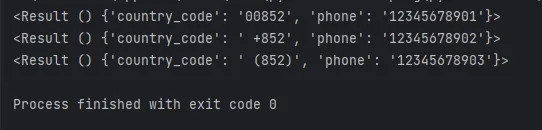
and my username is {username}.Or you want to extract multiple phone numbers. Still, the phone numbers have different formats of country codes in front, and the phone numbers are of a fixed length of 11 digits. You can write it like this:
compiler = Parser("{country_code}{phone:11.11},")
content = "0085212345678901, +85212345678902, (852)12345678903,"
results = compiler.findall(content)
for result in results:
print(result)Or if you need to process a piece of text in an HTML tag, but the text is preceded and followed by an indefinite length of whitespace, you can write it like this:
content:
<div> Hello World </div>
pattern:
<div>{:^}</div>In the code above, {:11} refers to the width, which means to capture at least 11 characters, equivalent to the regular expression (.{11,})?. {:.11} refers to the precision, which means to capture at most 11 characters, equivalent to the regular expression (.{,11})?. So when combined, it means (.{11, 11})?. The result is:
The most powerful feature of parse is its handling of time text, which can be directly parsed into Python datetime objects. For example, if we want to parse the time in an HTTP log:
content:
[04/Jan/2019:16:06:38 +0800]
pattern:
[{:th}]Retrieving results
There are two ways to retrieve the results:
- For capturing methods that use
{}without a field name, you can directly useresult.fixedto get the result as a tuple. - For capturing methods that use
{field_name}, you can useresult.namedto get the result as a dictionary.
Custom Type Conversions
Although using {field_name} is already quite simple, the source code reveals that {field_name} is internally converted to (?P<field_name>.+?). So, parse still uses regular expressions for matching. .+? represents one or more random characters in non-greedy mode.

However, often we hope to match more precisely. For example, the text “my email is xxx@xxx.com”, “my email is {email}” can capture the email. Sometimes we may get dirty data, for example, “my email is xxxx@xxxx”, and we don’t want to grab it.
Is there a way to use regular expressions for more accurate matching?
That’s when the with_pattern decorator comes in handy.
For example, for capturing email addresses, we can write it like this:
@with_pattern(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b')
def email(text: str) -> str:
return text
compiler = Parser("my email address is {email:Email}", dict(Email=email))
legal_result = compiler.parse("my email address is xx@xxx.com") # legal email
illegal_result = compiler.parse("my email address is xx@xx") # illegal emailUsing the with_pattern decorator, we can define a custom field type, in this case, Emailwhich will match the email address in the text. We can also use this approach to match other complicated patterns.
A Real-world Example: Parsing Nginx Log
After understanding the basic usage of parse, let’s return to the troubles of Wang mentioned at the beginning of the article. Let’s see how to parse logs if we have server log files for the past month.
💡 Unlock Full Access for Free!
Subscribe now to read this article and get instant access to all exclusive member content + join our data science community discussions.



