
Aiomultiprocess: Super Easy Integrate Multiprocessing & Asyncio in Python
Even no need to know much about asyncio and multiprocessing


In this article, I will introduce how to integrate multiprocessing and asyncio using the aiomultiprocess library easily. The article includes a web scraping project example and the best practices for using this library.
Introduction
My colleague Wang came to me today and said that his boss assigned him a new task: to write web scraping code to fetch information from 1,000 books on books.toscrape.com as quickly as possible.
Wang told me: “I’ve read your related articles, and since the boss has performance requirements, why don’t I write one using asyncio? It doesn’t seem too difficult.”
“30.09 seconds,” I told him a number.
“What’s that?” Wang asked.
I said I had just tried it and that only using concurrent tasks with asyncio for web scraping would take that long on my computer. This speed is already relatively fast.
“12.64 seconds,” I told him another number.
The speed doubled! Wang was stunned.
Because I used a mighty library called aiomultiprocess, which can easily integrate multiprocessing and asyncio. And the performance can be improved by modifying the web scraping code with aiomultiprocess on the same network and computer.
Multiprocessing and Asyncio: A Quick Recap
Wang said: “That’s amazing! Teach me how to use aiomultiprocess quickly!”
I told him not to hurry. Although the library is simple enough that he doesn’t need to understand what asyncio and multiprocessing are, I still need to give some theoretical introductions to help him truly master the implementation principles of this library.
Key concepts of asyncio
Asyncio is a new feature introduced in Python 3.4. Its main part is to execute code snippets in a loop through an event loop in the main thread.
Users can switch to another task while waiting for a network call (or disk read/write) to return.
Since it is single-threaded and not constrained by the GIL, asyncio is very suitable for executing IO-bound code.
Key concepts of multiprocessing
Multiprocessing is a feature introduced in Python for compute-intensive tasks. Its principle is to use multiple processes to execute different Python codes in parallel.
It makes full use of the performance of multi-core CPUs, so it is very suitable for running CPU-bound code.
Benefits of combining both approaches
However, using asyncio or multiprocessing alone is only ideal in specific situations. In reality, the boundaries between IO-bound and CPU-bound tasks are not so clear.
Take the web scraping scenario as an example:
Web scraping is divided into two parts: fetching the HTML of the page from the network and parsing the required content from the HTML. The former is an IO-bound task, and the latter is a CPU-bound task.
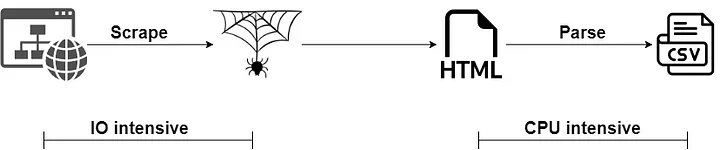
This brings us a problem: if we only use asyncio, and the CPU time slice occupied by the CPU-bound task is too long, the single-threaded calculation performance will not be ideal.
If we only use multiprocessing, the number of CPU cores will limit the concurrency.
In a previous article, I introduced a way to integrate asyncio and multiprocessing. Specifically:
In the main process’s event loop, use loop.run_in_executor to start multiple subprocesses.
Then, use asyncio.run in each subprocess to create an event loop individually.
The diagram is as follows:
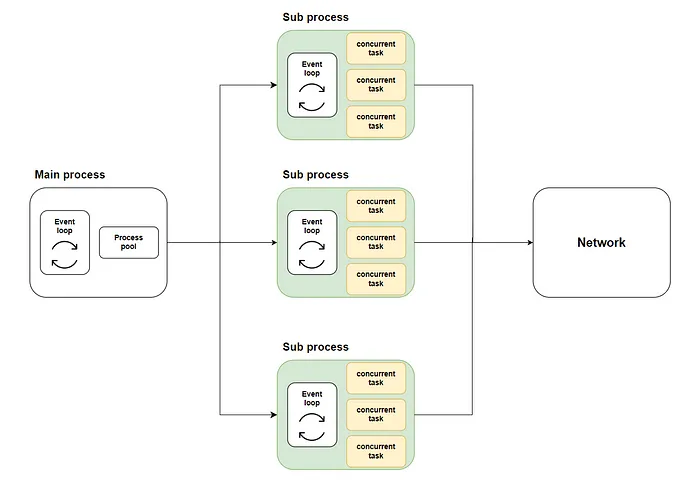
However, this method has several problems:
- It requires understanding more low-level asyncio and multiprocessing APIs, which is impractical.
- It requires calculating which task to execute in which process initially without a flexible task allocation mechanism.
- Due to mixing concurrent and parallel mechanisms, using queues or other methods to communicate between multiple tasks is challenging.
- It is difficult to add new tasks during code execution.
In summary, this method is too low-level and thus difficult to use.
The aiomultiprocess library, which perfectly encapsulates the underlying code and exposes only a few upper-layer interfaces, can help us solve these problems well.
Getting Started with Aiomultiprocess
Installation and setup
If you’re using pip:
Python -m pip install aiomultiprocessIf you’re using Anaconda since the default channel does not contain this package, use:
conda install -c conda-forge aiomultiprocessBasic syntax and setup
By examining the source code or referring to the official documentation, we can find that aiomultiprocess only requires three classes:
Process: Executes a coroutine task within a subprocess. It’s not commonly used, but theWorkerandPoolclasses inherit it.Worker: Executes a coroutine task within a subprocess and returns the result. You can use this class to modify an existing coroutine function to run in a subprocess.Pool: The core class we’ll be using. It aims to launch a process pool and allocate each coroutine task to a subprocess for execution. This class has two methods to master:
map: Takes a task function (coroutine function) and an iterable object as arguments. It applies each item in the iterable as an argument to the task function, running it in a subprocess. The method returns a generator object, and you can useasync forto retrieve each value in the result.
import asyncio
import random
import aiomultiprocess
async def coro_func(value: int) -> int:
await asyncio.sleep(random.randint(1, 3))
return value * 2
async def main():
results = []
async with aiomultiprocess.Pool() as pool:
async for result in pool.map(coro_func, [1, 2, 3]):
results.append(result)
# The result depends on the order in which the parameters are passed in,
# not on which task end first
# Output: [2, 4, 6]
print(results)
if __name__ == "__main__":
asyncio.run(main())apply: Takes a task function, as well asargsandkwargs. It combines the task function withargsandkwargs, runs them in a subprocess, and returns an asyncio task. You can obtain all task results usingasyncio.gather.
import asyncio
import random
import aiomultiprocess
async def coro_func(value: int) -> int:
await asyncio.sleep(random.randint(1, 3))
return value * 2
async def main():
tasks = []
async with aiomultiprocess.Pool() as pool:
tasks.append(pool.apply(coro_func, (1,)))
tasks.append(pool.apply(coro_func, (2,)))
tasks.append(pool.apply(coro_func, (3,)))
results = await asyncio.gather(*tasks)
print(results) # Output: [2, 4, 6]
if __name__ == "__main__":
asyncio.run(main())Understanding the key components
Before diving into aiomultiprocess examples, we need to understand the implementation principles of the Pool class.
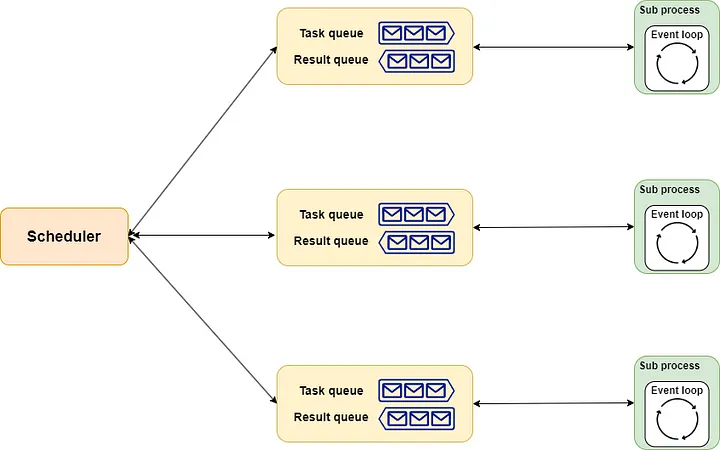
Pool mainly consists of three modules: scheduler, queue, and process. Among them:
- The
schedulermodule is responsible for task allocation. The defaultschedulerevenly distributes tasks across subprocesses in the order they are received. You can also implement a priority-based scheduler usingPriorityQueue. - The
queuemodule contains task and result queues, connecting theschedulerandsubprocesses. Both queues are implemented usingmultiprocessing.Manager().Queue(). It is responsible for passing tasks to the subprocesses and returning results from the subprocesses. - The
processmodule is implemented with theProcessclass, which acquires subprocesses through thespawnmethod by default. An event loop is created in each subprocess. The results of the loop execution are passed back to the main process through the result queue.
The entire schematic diagram is as follows:
Real-world Example: Web Scraping with Aiomultiprocess
After introducing the basic usage and implementation principles of aiomultiprocess, I’ll now fulfill my promise to demonstrate how aiomultiprocess can easily improve existing code and achieve significant performance improvements.
First, let me show you the asyncio version of the web scraping code. The goal of this code is simple: to fetch links to detail pages from 50 list pages on books.toscrape.com, extract the desired book data from the detail pages, and finally write it to a CSV file:
import asyncio
import csv
import time
from string import Template
from urllib.parse import urljoin
from aiohttp import request
from aiomultiprocess import Pool
from bs4 import BeautifulSoup
list_url_t = Template("https://books.toscrape.com/catalogue/category/books_1/page-$page.html")
def get_detail_url(base_url: str, html: str) -> list[str]:
""" Grab the link to the detail page of each book from the HTML code of the list page """
result = []
soup = BeautifulSoup(html, "html.parser")
a_tags = soup.select("article.product_pod div.image_container a")
for a_tag in a_tags:
result.append(urljoin(base_url, a_tag.get("href")))
return result
def parse_detail_page(html):
""" Parse the HTML of the detail page to get the desired book data """
soup = BeautifulSoup(html, "lxml")
title = soup.select_one("div.product_main h1").text
price = soup.select_one("div.product_main p.price_color").text
description_tag = soup.select_one("div#product_description + p")
description = description_tag.text if description_tag else ""
return {"title": title, "price": price, "description": description}
async def fetch_list(url: str) -> list[str]:
""" Get the URL of each detail page from the list page URL """
print(f"fetch_list: begin to process url: {url}")
async with request("GET", url) as response:
html = await response.text()
urls = get_detail_url(url, html)
return urls
async def fetch_detail(url: str) -> dict:
""" Get the book data on the detail page from the detail page URL """
async with request("GET", url) as response:
html = await response.text()
detail = parse_detail_page(html)
return detail
def write_to_csv(all_books: list):
""" Writing data to CSV files """
print(f"write_to_csv: begin to write books detail to csv.")
with open("../../raw_data/scraping_result.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = all_books[0].keys()
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writerows(all_books)
async def asyncio_main():
""" Implementing web scraping by using asyncio alone """
start = time.monotonic()
all_books, detail_urls = [], []
fetch_list_tasks = [asyncio.create_task(fetch_list(list_url_t.substitute(page=i + 1))) for i in range(50)]
for urls in asyncio.as_completed(fetch_list_tasks):
detail_urls.extend(await urls)
fetch_detail_tasks = [asyncio.create_task(fetch_detail(detail_url)) for detail_url in detail_urls]
for detail in asyncio.as_completed(fetch_detail_tasks):
all_books.append(await detail)
write_to_csv(all_books)
print(f"All done in {time.monotonic() - start} seconds")
if __name__ == "__main__":
asyncio.run(asyncio_main())
Next, we only need to modify the main function, using aiomultiprocess’s Pool and corresponding APIs to start the web scraping code. The original logic code does not need to be changed:
async def aiomultiprocess_main():
"""
Integrating multiprocessing and asyncio with the help of aiomultiprocess,
requires only a simple rewriting of the main function
"""
start = time.monotonic()
all_books = []
async with Pool() as pool:
detail_urls = []
async for urls in pool.map(fetch_list,
[list_url_t.substitute(page=i + 1) for i in range(50)]):
detail_urls.extend(urls)
async for detail in pool.map(fetch_detail, detail_urls):
all_books.append(detail)
write_to_csv(all_books)
print(f"All done in {time.monotonic() - start} seconds")
if __name__ == "__main__":
asyncio.run(aiomultiprocess_main())
This way, a purely asyncio-based code is transformed into a version that integrates multiprocessing and asyncio. Isn’t it super simple?
Best Practices for Using Aiomultiprocess
aiomultiprocess.Pool provides parameters like process, queuecount, and childconcurrency for performance tuning. In the following sections, I’ll explain various methods of optimization based on different scenarios.
Computation-intensive scenarios
In this case, a task consumes significant processing time, leading to delayed IO responses when running high concurrency on a single process.
To optimize, we can reduce the values of childconcurrency and queuecount while moderately increasing the process.
High IO, high latency scenarios
In this scenario, the IO pressure is relatively high, and the process needs to frequently switch between multiple IOs to promptly respond to IO returns. Here, we can increase childconcurrency to enhance each process’s concurrency.
High concurrency, high throughput scenarios
The queue is filled with numerous tasks in this situation, and multiple processes compete for queue resources.
We can increase queuecount (but stay within the number of processes) to ensure that each process has sufficient queues for task allocation.
Uneven task execution time scenarios
Sometimes, some tasks require a lot of time for computation, such as parsing complex web pages. Others need substantial time to wait for IO, like writing massive amounts of data to a database.
This results in task skew, with uneven pressure on processes executing tasks. Some processes quickly complete tasks and enter the waiting state, but others still need considerable time to finish the remaining tasks.
In this case, we can execute different types of tasks separately, completing simple tasks first and tackling the more complex ones.
Alternatively, we can lower the queuecount value to ensure fewer tasks enter the waiting queue, distributing tasks evenly among processes.
We can also implement a custom scheduler to prioritize specific tasks, reducing task skew.
Conclusion
It’s best to combine concurrent and parallel code to maximize code performance. However, integrating asyncio and multiprocessing code requires interacting with many low-level APIs and writing a lot of foundational code, which can be daunting for many readers.
aiomultiprocess solves this issue by enabling existing asyncio code to run on multiprocessing without any modifications. It simply utilizes its API calls, resulting in significant performance improvements.
I hope you enjoy coding! If you’re interested in any of the points discussed in this article, please feel free to leave a comment and engage in discussion.



