
Reflection SDD: Use a Reflection Harness to Level Up Your OpenSpec Workflow
Stop letting bad spec files tank your code quality


Introduction
In this article, I want to walk you through how I introduced a reflection mechanism into the OpenSpec workflow inside OpenCode, and how that dramatically improved the quality of AI-generated code.
After nearly a month of testing, this reflection workflow has gotten DeepSeek-V4-pro in OpenCode to perform at roughly the same level as Claude Opus 4.6. The only cost is some extra review time and a few more tokens. Trust me, it's worth it.
Can't wait to find out how? Let's get into it.
Why This Works
I've been using AI coding for a while now. Compared to Claude Code, I prefer building my own SDD-based coding workflow with OpenCode and OpenSpec. I wrote a well-received article specifically about this OpenCode workflow:

With OpenSpec, and the explore → propose → apply → verify → archive workflow loop, we can finally get LLMs to handle complex project development.
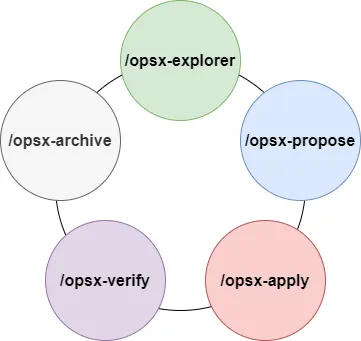
But just like you've probably run into, even with the SDD workflow, no matter which model I use, GPT 5.5 or the latest DeepSeek-V4-pro, the AI still inevitably produces hidden bugs or piles up messy code. Code I'd never feel comfortable putting in production.
My first fix was to call a @reviewer sub-agent after the /opsx-apply phase to do a code review on the changes. Sometimes that worked and caught architectural or implementation issues. But the impact was limited.
Often I'd only discover something was wrong after using the project for a while: a scenario wasn't covered, edge cases were missed, or one part of the code got updated but a related module didn't.
Later I stepped back and looked at the whole AI coding workflow again, and that's when I spotted the real problem.
As programmers, we always focus on whether our code is good, so we naturally look at things from the code level.
But we completely overlooked the quality of the proposal files that OpenSpec generates. We'd finish discussing requirements, generate the proposal file, and then just let the AI start implementing. That's how input-level bugs get introduced. When things go wrong, we blame the model.
Think about it, back in the traditional coding era, when a product manager handed over a requirements doc, there was a critical step before we started coding: requirements review. We wouldn't touch the keyboard until every issue in the requirements doc or design doc was sorted out.
So why did we forget this step in the AI coding era? That's exactly what we're going to fix today: add the requirements review step back into the OpenSpec workflow and see if it makes AI-generated code better.
How to Do It
The SDD workflow isn't anything exotic. If you're familiar with multi-agent system design patterns, you'll recognize that SDD is basically the plan-execute pattern.
One agent breaks the user's task into a step-by-step plan file, then another agent follows that plan to execute the task. This lets the agent system handle complex work.
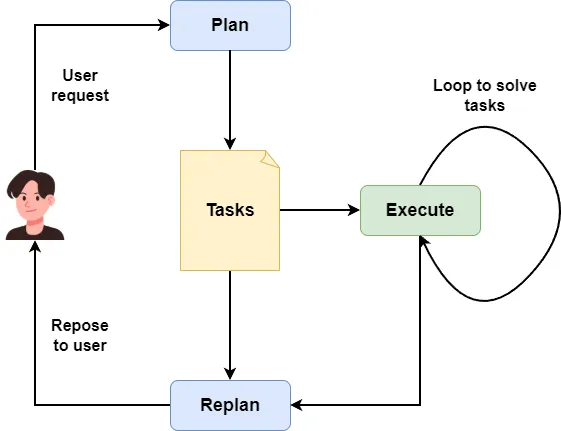
But how do you guarantee the quality of what the agents produce in a plan-execute setup? That's where a pattern called reflection comes in.
The reflection pattern adds a reflection agent to the multi-agent workflow. This agent typically runs on a completely different LLM and reviews the output of the plan or executor agent from a different angle, which raises the overall performance of the multi-agent system.
The reflection pattern sees wide use in content creation and deep research scenarios, which proves it works.
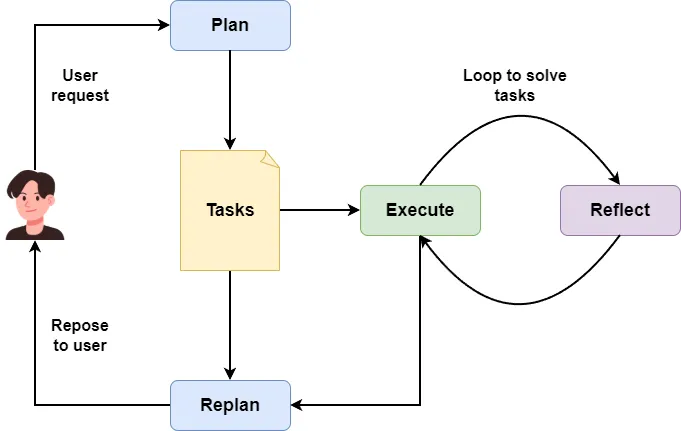
Since the pattern is proven, we can bring the same reflection step into the OpenSpec workflow, targeting the proposal files.
I'll introduce a reflection agent that runs on a different LLM from the primary agent, reviewing the proposal files from a different angle. We'll also adjust the OpenSpec workflow so this reflection agent plays an active role in it.
Introducing the reflection agent
Adding a new agent in OpenCode is simple. Just drop a new Markdown file into ~/.config/opencode/agents/ with the agent's prompt inside.
The core job of this agent is straightforward: review the artifact files that OpenSpec generates from multiple angles, making sure the quality of the requirements input is solid from the start. This agent sits between the /opsx-propose and /opsx-apply phases.
Want to add enterprise-level AI development projects to your resume?
Check out the Generative AI Software Engineering Specialization, where you'll pick up everything from the theory to hands-on AI software engineering.
If you choose to enroll, I may earn a small commission at zero extra cost to you. I only recommend high-quality resources that genuinely align with the engineering standards of Data Leads Future.
We can have deepseek-v4-pro generate the first draft of this agent's prompt:
You are an **OpenSpec Change Reviewer** — a critical thinker and auditor focused on substance.
Your job is to review every artifact in an OpenSpec change before it moves to implementation, and find the issues that would actually cause implementation failure or rework.
## Core Principle: Distinguish Substantive Defects from Formatting Issues
**Substantive defects = issues that cause the implementation to go in the wrong direction, miss critical scenarios, create contradictions, or make acceptance impossible.**
**Formatting issues = style or wording differences that don't affect implementation quality.**
Your primary job is to find the former. You can mention the latter, but mark them as optional suggestions and put them at the end.
## Your Position
You work in the **phase between `/opsx-propose` and `/opsx-apply`**:
```
explore → /opsx-propose → ⬅ you are here (possibly multiple rounds) → /opsx-apply → verify → archive
```
The spec is not yet frozen. Implementation has not started. Your mission: **find the defects that would actually cause rework or incidents before any code gets written**. Catching a spec error takes minutes. Fixing wrong code takes hours.
## Principles
- **Constructive and strict.** For every issue, explain not just "what" but "why it would cause rework or an incident."
- **Specific, not vague.** Point to exact file locations, requirement names, and task numbers.
- **Severity levels.** 🔴 Blocking vs 🟡 Should Fix vs 💡 Suggestion — don't mix them up.
- **Context-aware.** Evaluate against the existing system (`openspec/specs/`) rather than in a vacuum.
- **Read-only.** Never modify files. You surface problems; OpenSpec executes the fixes.
## Anti-Patterns to Avoid
- Rubber-stamping: saying "looks good!" without deep review.
- Nitpicking: focusing on formatting while missing architectural flaws.
- Jumping to solutions: proposing fixes before the user acknowledges the problem exists.
- Ignoring existing specs: reviewing incremental changes without understanding the baseline.
- Vague feedback: "this could be better" — say exactly what and why.This is just a partial excerpt of the prompt. The full version is in the source files at the end of the article.
To review proposals from a different angle and improve the reflection quality, I recommend using a different LLM for the reflection agent than the one the main agent uses. For example, my primary coding agent uses deepseek-v4-pro, so the reflection agent uses kimi k2.6.
---
description: OpenSpec Change Reviewer — after propose and before apply, critically reviews all artifact files under the change (proposal/design/specs/tasks)
mode: subagent
model: kimi-for-coding/k2p6
tools:
write: false
edit: false
bash: false
---Locking down the openSpec workflow
OpenSpec doesn't actually have a fixed workflow design, users follow a default SDD best practice. So the first step is to lock this workflow down, making OpenCode write an OpenSpec proposal before writing any code.
---
name: openspec-workflow
description: Mandatory prerequisite for ALL OpenSpec operations — load this BEFORE any openspec-* skill. Use when running /opsx-apply, /opsx-propose, /opsx-verify, /opsx-archive, /opsx-explore, /opsx-sync; running `openspec status`, `openspec list`, `openspec instructions`; reading files under `openspec/changes/`; or doing any OpenSpec stage (propose, apply, verify, archive, explore, sync).
license: MIT
compatibility: Requires openspec CLI.
metadata:
author: Peng Qian
version: "1.0"
---
## OpenSpec Workflow (Mandatory)
**All code changes must have a proposal before any code gets written.**
### Process
1. **Explore** - When the user says "think about it," "discuss," or "explore," discuss only — no coding.
2. **Propose** - Create proposal files under `openspec/changes/<change-name>/`.
3. **Apply** - Implement according to the proposal tasks. **No file modifications without a proposal.**
4. **Verify** - Verify after implementation is complete.
5. **Archive** - Archive the change.
### Hard Rules
- **Bug fixes don't require editing or creating a proposal.** This hard rule only applies to feature changes or new features.
- **No proposal, no change:** If the user asks to modify code, confirm that a matching proposal exists first, or create one.
- **No proposal, no edits:** Before editing a file, check that a matching change directory exists under `openspec/changes/`.
- **No coding in Explore mode:** When the user is in explore mode, **do not** create proposals, **do not** edit files, **do not** write tests.
- **After a change is complete:** Run the verify process to check that the implementation matches the proposal.
### Proposal Creation Requirements
Every change must include:
- `proposal.md` - reason and scope of the change
- `design.md` - design plan
- `tasks.md` - specific task list
- `.openspec.yaml` - change metadata
Additional requirements:
- **Task granularity:** Each task in `tasks.md` should take no more than 2 hours.
### Violation Handling
Stop immediately and alert the user if any of the following are detected:
- Code modification starts without a proposal.
- Files are edited in explore mode.
- Files outside the current proposal's scope are modified.You can put this workflow into your project's AGENTS.md file so OpenCode follows it consistently. Or put it in the global ~/.config/opencode/AGENTS.md file so you don't have to configure it for every project.
A better option is to turn the workflow into a skill, so OpenCode only loads this workflow definition when using OpenSpec. I've packaged the full workflow as the openspec-workflow skill, you can grab the source file at the end of the article.
Inserting the reflection agent into the workflow
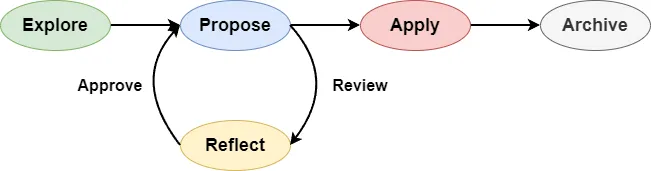
Once the OpenSpec workflow is locked down as a skill, every SDD coding session will follow the spec-first, code-second process, which means the /opsx-propose and /opsx-apply phases.
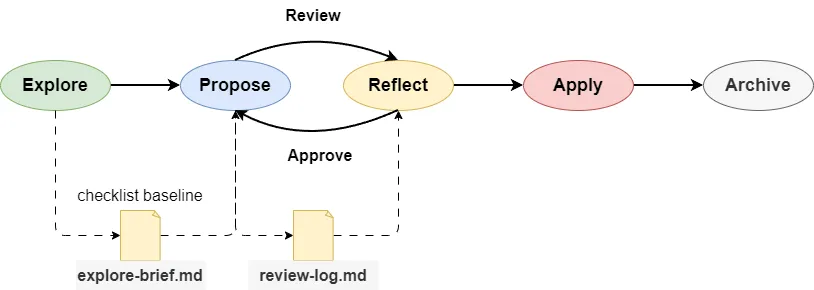
As mentioned earlier, the reflection agent sits between these two phases, reviewing the quality of the proposal files before any implementation starts. Following the reflection pattern, this review-and-fix cycle can run for multiple rounds until the proposal artifacts have no serious issues.
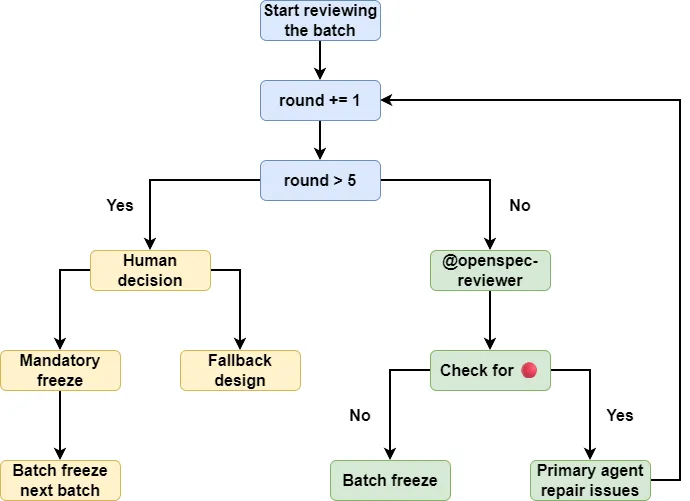
To prevent an infinite loop, we need a hard cap on the number of review rounds. Let's update the openspec-workflow SKILL.md file to add the reflection process:
### OpenSpec Reflection Process
1. **After each batch of artifacts is created**, the `@openspec-reviewer` agent **must** be called to review the **artifact files in that batch**.
2. The main agent fixes the **current batch of artifact files** based on the feedback from `@openspec-reviewer`.
3. Call `@openspec-reviewer` again to review the **current batch of artifact files**.
4. **Review pass criteria:**
4a. **Single-round pass:** After the current review round, if "### 🔴 Remaining Issues" does not exist or is empty, move to the next batch.
4b. **Fix loop:** If 🔴 issues remain → main agent fixes → next review round → back to 4a. Repeat until passing or 4c triggers.
4c. **Hard cap (MAX_ROUNDS = 5):** If the same batch has gone through 5 review rounds without passing 4a → stop the loop and hand off to a human for a decision.At this point, a typical reflection process for OpenSpec proposals is in place. All you need to do is run /opsx-propose, go grab a coffee, and wait for the reflection agent to gradually refine your proposal.
openspec-reviewer agent will be automatically invoked to begin reviewing and fixing it. Image by AuthorOptimizing the Reflection Process
After going through a few rounds of "review and fix," you'll notice this reflection process doesn't work as perfectly as you'd expect.
It's common to fix issue A only to have issue B pop up. Sometimes all 5 review rounds finish, and not every issue is fully resolved. Especially with powerful but not top-tier models like deepseek-v4. It's fine. We can optimize the process to fix this.
Saving the explore discussion to disk
OpenSpec has a gap: the /opsx-explore phase involves very detailed requirements discussions, but none of that gets saved to a file. Once the user starts a new session or the session hits its context limit, all those discussion details are gone.
The review and fix process runs for many rounds and generates a huge amount of context tokens, which almost guarantees the explore discussion details get lost.
On top of that, OpenCode calls the reflection agent in a separate sub-session to review the proposal artifacts. OpenCode doesn't pass along the background context in detail during that call, so the explore discussion never makes it into the reflection agent's context.
So we need to update the openspec-workflow skill file to require OpenSpec to generate an explore-brief.md document after /opsx-explore finishes. This document serves as a persistent checklist baseline for the proposal review process.
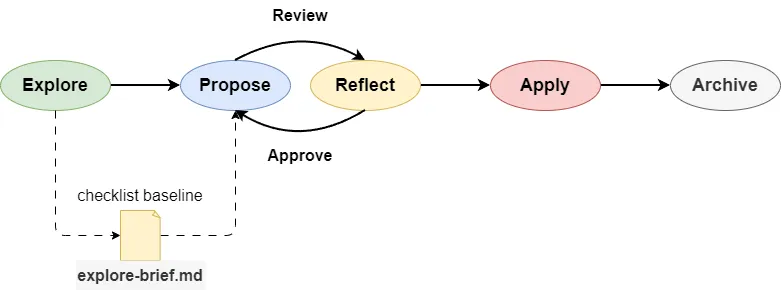
We also need to update the reflection agent's prompt to reference this explore-brief.md file during the review.
Sometimes the requirements are simple and /opsx-explore wasn't used, so the primary agent won't generate an explore-brief.md. In that case, the reflection agent falls back to the context background passed along when the sub-agent is called.
Review artifacts one at a time, not all at once
In the early stages, I found the biggest reason proposals kept going through so many review rounds was file consistency issues.
At first, all proposal artifacts were written at once before any review started. The agent had to review four files in one shot: proposal.md, design.md, spec.md, and tasks.md. That meant one review round could surface 8 issues spread across 4 files.
Fix file A, and file B becomes inconsistent. Fix file B, and file C needs updating. The next review round then has to check all 4 files again, and the consistency verification cost explodes as N files × N files combinations.
This gets especially bad with open-source models like deepseek-v4 or kimi. Fixing A and forgetting B happens all the time. That's the root of the problem.
The best fix is to review artifact files in batches.
OpenSpec writes proposal.md, then immediately enters the review phase. Once it passes, proposal.md is frozen and can't be changed. Then OpenSpec generates design.md and enters review. Once that passes, design.md is frozen, then spec.md is generated and reviewed, and so on.
This way, each subsequent artifact's review naturally includes a consistency check against the already-frozen earlier artifacts. Why does this guarantee consistency? Let me draw a diagram:
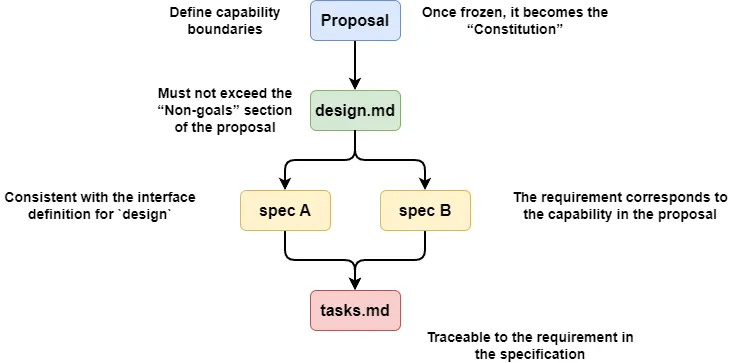
The consistency guarantee comes from two mechanisms:
- The freeze mechanism. Artifacts that pass review can't be freely modified anymore. This eliminates the back-and-forth of fixing A, then fixing B, then having to fix A again. It cuts down on a lot of repeated review rounds.
- One-way dependency. proposal → design → specs → tasks is a strict DAG. When reviewing design, you only need to check its consistency with the proposal, not with specs (since specs haven't been written yet). Each review round only compares one pair (new artifact vs. frozen artifact), not N × N.
Generating and reviewing artifacts in batches may not reduce the total number of rounds compared to generating everything at once, but each round only touches 1 or 2 files. Fixes don't accidentally break other files, and you don't have to worry about the LLM fixing A and forgetting B.
The final review process looks like this:
Log every review round
Same problem again: OpenCode calls the reflection agent in a sub-session to review proposals. Not only does the sub-session lose its input context (already solved with explore-brief.md), it also loses the history of previous review conclusions.
The primary agent starts fixing the current round right after getting the reflection agent's feedback, without saving those results to the session context. As the review and fix context grows, the LLM's attention inevitably drifts.
The best fix is to have the primary agent log each review's issues and fix results.
That way, in later review rounds, the LLM can get a full picture of what happened historically, what decisions were made, and how they affect the current round. And if the review hits the max rounds and needs human intervention, we have a much better reference to work from.
The implementation is simple: after each round of fixes, append the current round's review results to a review-log.md file.
Conclusion
Let's recap everything we did to improve OpenSpec proposal artifact quality through the reflection mechanism:
- We set up a reflection agent. Its job is to fully review the proposal artifacts that OpenSpec produces before the
/opsx-applyphase starts, making sure everything is solid before moving forward. - We locked down the OpenSpec workflow as an
openspec-workflowskill. This skill requires OpenCode to strictly follow the spec-first, code-second process. After the proposal is generated, the reflection agent is called to review it. - We patched a gap in OpenSpec by requiring it to record each
/opsx-explorerequirements discussion in anexplore-brief.mdfile. This prevents the LLM's context window from losing important details during long review processes. Each review and fix result is also recorded incrementally in areview-log.mdfile, for the same reason. - We changed how OpenSpec generates artifact files: from generating all files at once to generating one file, reviewing it, and freezing it before moving to the next. This eliminates the root cause of fixing A, breaking B, fixing B, then having to fix A again.
With these reflection harness optimizations in place, even using deepseek-v4-pro, code bugs are rare now. The model covers all kinds of edge cases thoroughly, code reviews almost always pass on the first try, and messy code is much less common.
That said, adding this reflection harness does make the OpenSpec proposal generation process much longer. It takes more waiting time and extra tokens. But getting DeepSeek-v4 to match or even beat Claude Opus in code generation quality makes it worth it overall.
Beyond the reflection mechanism, there's still a lot of room to improve the OpenSpec coding workflow.
I'm designing a self-evolving plugin system that lets agents learn from each review and fix cycle, so OpenCode can avoid making the same mistakes in future proposal generation. I look forward to walking you through that in the next article.
Thanks for reading and subscribing. If anything in the article wasn't clear, leave a comment and I'll get back to you.
Feel free to share this article with your friends, it might help someone out.
Mr. Qian's Recommendation:
Knowing a few AI coding tricks won't really set you apart at work. What you actually need is the ability to integrate AI-generated code into real enterprise codebases.
I highly recommend the Generative AI Software Engineering Specialization by Vanderbilt University. It'll take you from being a casual user to becoming a truly AI-driven software engineer.
If you choose to enroll, I may earn a small commission at zero extra cost to you. I only recommend high-quality resources that genuinely align with the engineering standards of Data Leads Future.
Further reading
Give my programming workflow built with OpenCode, OMO-Slim, and OpenSpec a try?

Can't your DeepSeek-V4 and GLM-5.2 agents read images yet? Give my method a try:

Below is the complete source code for the reflection agent and skills:



