
Python Lists Vs. NumPy Arrays: A Deep Dive into Memory Layout and Performance Benefits
Exploring allocation differences and efficiency gains


In this article, we will delve into the memory design differences between native Python lists and NumPy arrays, revealing why NumPy can provide better performance in many cases.
We will compare data structures, memory allocation, and access methods, showcasing the power of NumPy arrays.
Introduction
Imagine you are preparing to go to the library to find a book. Now, you discover that the library has two shelves:
The first shelf is filled with various exquisite boxes, some containing CDs, some containing pictures, and others containing books. Only the name of the item is attached to the box.
This represents native Python lists, where each element has its memory space and type information.
However, this approach has a problem: many empty spaces in the boxes, wasting shelf space. Moreover, when you want to find a specific book, you must look inside each box, which takes extra time.
Now let’s look at the second shelf. This time there are no boxes; books, CDs, and pictures are all compactly placed together according to their categories.
This is NumPy arrays, which store data in memory in a continuous fashion, improving space utilization.
Since the items are all grouped by category, you can quickly find a book without having to search through many boxes. This is why NumPy arrays are faster than native Python lists in many operations.
Python Lists: A Flexible but Less Efficient Solution
Everything in Python is an object
Let’s start with the Python interpreter: although CPython is written in C, Python variables are not basic data types in C, but rather C structures that contain values and additional information.
Take a Python integer x = 10_000 as an example, x is not a basic type on the stack. Instead, it is a pointer to a memory heap object.
If you delve into the source code of Python 3.10, you’ll find that the C structure that x points to is as shown in the following figure:

The PyObject_HEAD contains information such as reference count, type information, and object size.
Python lists are objects containing a series of objects
From this, we can deduce that a Python list is also an object, except that it contains pointers to other objects.
We can create a list that contains only integers:
integer_list = [1, 2, 3, 4, 5]We can also create a list that includes multiple object types:
mixed_list = [1, "hello", 3.14, [1, 2, 3]]Pros and cons of Python lists
As we can see, Python lists contain a series of pointer objects. These pointers, in turn, point to other objects in memory.
The advantage of this approach is flexibility. You can put any object in a Python list without worrying about type errors.
However, the downside is also evident:
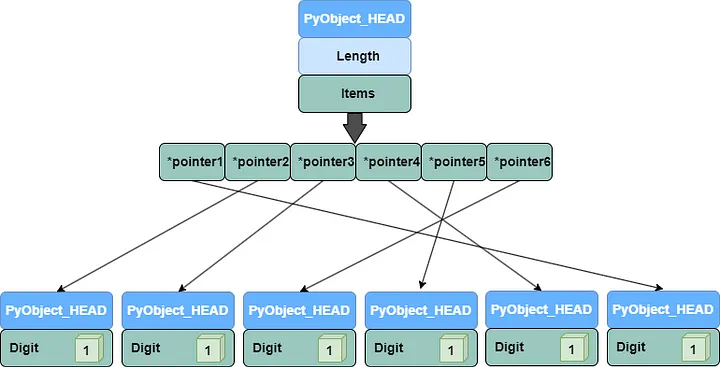
The objects pointed to by each pointer are scattered in memory. When you traverse a Python list, you need to look up the memory location of each object based on the pointer, resulting in lower performance.
NumPy Arrays: A Contiguous Memory Layout for Enhanced Performance
Next, let’s explore the components and arrangement of NumPy arrays, and how it benefits cache locality and vectorization.
NumPy arrays: structure and memory layout
According to NumPy’s internal description, NumPy arrays consist of two parts:
- One part stores the metadata of the NumPy array, which describes the data type, array shape, etc.
- The other part is the data buffer, which stores the values of array elements in a tightly packed arrangement in memory.
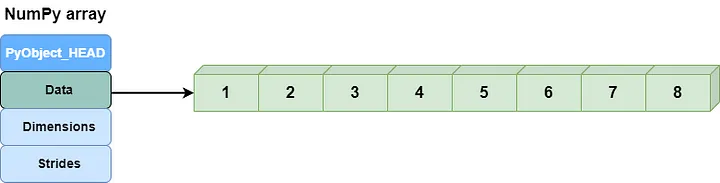
Memory layout of NumPy arrays
When we observe the .flags attribute of a ndarray, we find that it includes:
In 1: np_array = np.arange(6).reshape(2, 3, order='C')
np_array.flags
Out 1: C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : FalseC_CONTIGUOUS, which indicates whether the data can be read using row-major order.F_CONTIGUOUS, which indicates whether the data can be read using column-major order.
Row-major order is the data arrangement used by the C language, denoted by order=’C’. It means that data is stored row by row.
Column-major order, on the other hand, is used by FORTRAN, denoted by order=’F’, and stores data column by column.
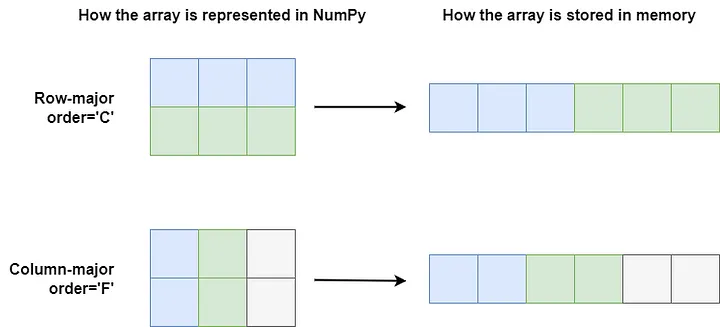
Advantages of NumPy’s memory layout
Since ndarray is designed for matrix operations, all its data types are identical, with the same byte size and interpretation.
This allows data to be tightly packed together, bringing advantages in cache locality and vectorized computation.
Cache Locality: How NumPy’s Memory Layout Improves Cache Utilization
What is CPU cache
NumPy’s contiguous memory layout helps improve cache hit rates because it matches how CPU caches work. To better explain this, let’s first understand the basic concept of CPU cache.
A CPU cache is a small, high-speed storage area between the CPU and main memory (RAM). The purpose of the CPU cache is to speed up data access in memory.
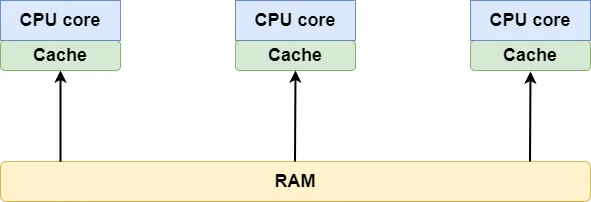
When the CPU needs to read or write data, it first checks if it is already in the cache.
The CPU can read directly from the cache if the required data is in the cache (cache hit). If the data is not present (cache miss), the CPU loads the data from RAM and stores it in the cache for future use.
CPU caches are usually organized in cache lines, which are contiguous memory addresses. When the CPU accesses RAM, the cache loads the entire cache line into the high-speed cache.
This means that if the CPU accesses neighboring memory addresses, subsequent accesses are more likely to hit the cache after loading a cache line, thus improving performance.
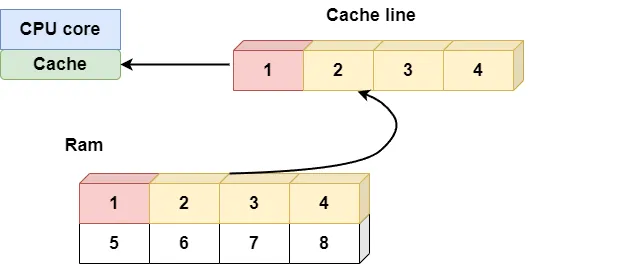
How NumPy utilizes cache
NumPy’s contiguous memory layout takes advantage of this fact.
NumPy arrays store data in continuous memory addresses, which helps improve cache locality.
When accessing an element in the array, the entire cache line (containing neighboring array elements) is loaded into the cache.
As you traverse the array, you access each element in a sequence. Because array elements are stored contiguously in memory, cache hits are more likely during the traversal, improving performance.
This is similar to going to the library to read a book. Instead of just grabbing the book you need, you also take out related books and place them on the table.
This way, when you need to consult associated materials, they’re easily accessible and more efficient than searching the shelves.
Vectorization: Unleashing the Power of NumPy’s Memory Layout
What is vectorization
Vectorization is a technique that leverages the Single Instruction Multiple Data (SIMD) features of CPUs or GPUs to perform multiple data operations simultaneously.
Vectorized operations can significantly improve code execution efficiency by simultaneously processing multiple data items.
NumPy’s contiguous memory layout facilitates vectorized operations.
Why is vectorization suitable
Consider yourself a delivery person who must deliver packages to various households daily.
Suppose the packages are arranged sequentially in the vehicle, and the houses are numbered along the street. In that case, the delivery person can efficiently deliver packages along the street in order.
This efficient method is analogous to NumPy’s memory layout, which brings the following benefits in vectorization:
- Data alignment: NumPy arrays’ contiguous memory layout ensures that data is aligned in memory in a vectorization-friendly manner. This allows the CPU to efficiently load and process data in NumPy.
- Sequential access pattern: NumPy’s tightly packed data in memory helps improve vectorization performance. The sequential access pattern also takes full advantage of CPU cache and prefetching, reducing memory access latency.
- Simplified code: NumPy offers a range of functions (e.g.,
np.add,np.multiply) and operations (e.g., array slicing) that automatically handle vectorized operations. You can write concise and efficient code without worrying about the underlying implementation.
Copies and Views: NumPy’s Excellent Design for Performance Optimization
In the earlier discussion, we discussed how NumPy leverages its contiguous memory layout to achieve performance advantages.
Now, let’s discuss how NumPy gains performance benefits through copies and views.
What are copies and views
Copies and views are two options that define the relationship between existing data and the original array. Based on the characteristics of these two options, they can be summarized as follows:
- Copy: Uses a different memory space than the original array, but the data content is the same.
- View: References the same memory address as the original array.
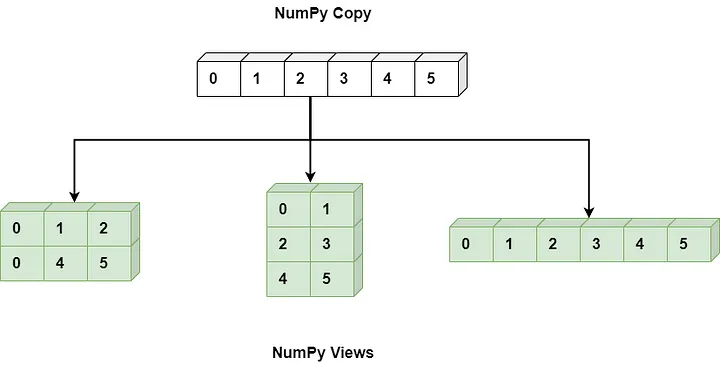
If we compare this to a book, a view is like a bookmark placed in the book, without creating a copy of the book.
On the other hand, a copy is a duplicate of the original book, containing a complete replica, including text and images. When you add notes to this copy, the original book remains unaffected.
Making good use of both features
Utilizing the characteristics of views and copies can help us write concise and efficient code.
Let’s take arithmetic operations as an example. A new copy will be created if you use a = a + 1. However, if you use a += 1 or np.add, broadcasting is applied, and the addition is performed directly on the original array.
Consider the following code, which measures the execution time:
import numpy as np
import time
def test():
x = np.ones(100_000_000, dtype='int8')
y = np.ones(100_000_000, dtype='int8')
start = time.monotonic()
for _ in range(100):
x = x * 4 + y * 3
x = np.ones(100_000_000, dtype='int8')
print(f'x = x * 4 + y * 3: needs {time.monotonic() - start:.2f} seconds.')
start = time.monotonic()
for _ in range(100):
x *= 4
x += y * 3
x = np.ones(100_000_000, dtype='int8')
print(f'x *= 4; x += y * 3: needs {time.monotonic() - start:.2f} seconds.')
start = time.monotonic()
for _ in range(100):
np.multiply(x, 4, out=x)
np.multiply(y, 3, out=y)
np.add(x, y, out=x)
x = np.ones(100_000_000, dtype='int8')
y = np.ones(100_000_000, dtype='int8')
print(f'use functions needs {time.monotonic() - start:.2f} seconds.')
if __name__ == "__main__":
test()Executing the above code will yield a result similar to the following:
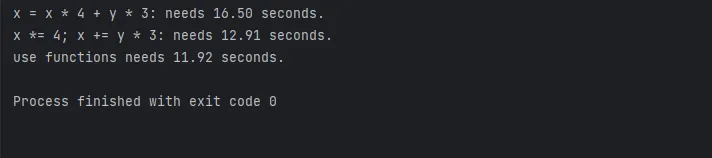
As we can see from the results, using views for calculations takes less time.
Distinguishing between copies and views
Confirming whether the result is a view or a copy every time a calculation is performed would require much effort.
However, there’s a more straightforward way to verify this:
- Use
may_share_memoryto determine if the two arrays in the argument refer to the same memory space. This judgment may not be strict. True doesn’t necessarily mean the arrays are shared, but False confirms that the arrays are definitely not shared. - If you need a more accurate answer, you can use the
share_memoryfunction. However, this function takes longer to execute thanmay_share_memory.
Conclusion
In summary, we have learned about the differences in memory arrangement between NumPy arrays and native Python lists.
Due to the contiguous arrangement of the same data type in NumPy’s array, significant performance advantages are achieved in both Cache Locality and Vectorization.
Separating views and copies in NumPy’s design provides greater flexibility for code execution performance and memory management.
In the upcoming series of articles, I will start from the basics and reiterate the best practices for data science at work. If you have any suggestions or questions, please feel free to comment, and I will address them individually.



