
My Agent System Looks Powerful but Is Just Industrial Trash
Single agent, low robustness, and position bias


This weekend note is a bit late because Phase One of my Deep Data Analyst project failed for now. That means I can’t continue the promised Data Analyst Agent tutorial.
What Happened?
I actually built a single-agent data analysis assistant based on the ReAct pattern.
This assistant could take a user’s analysis request, come up with a reasonable hypothesis, run EDA and modeling on the uploaded dataset, give professional business insights and actionable suggestions, and even create charts to back up its points.
If you’re curious about how it worked, here’s a screenshot that shows how cool it looked:
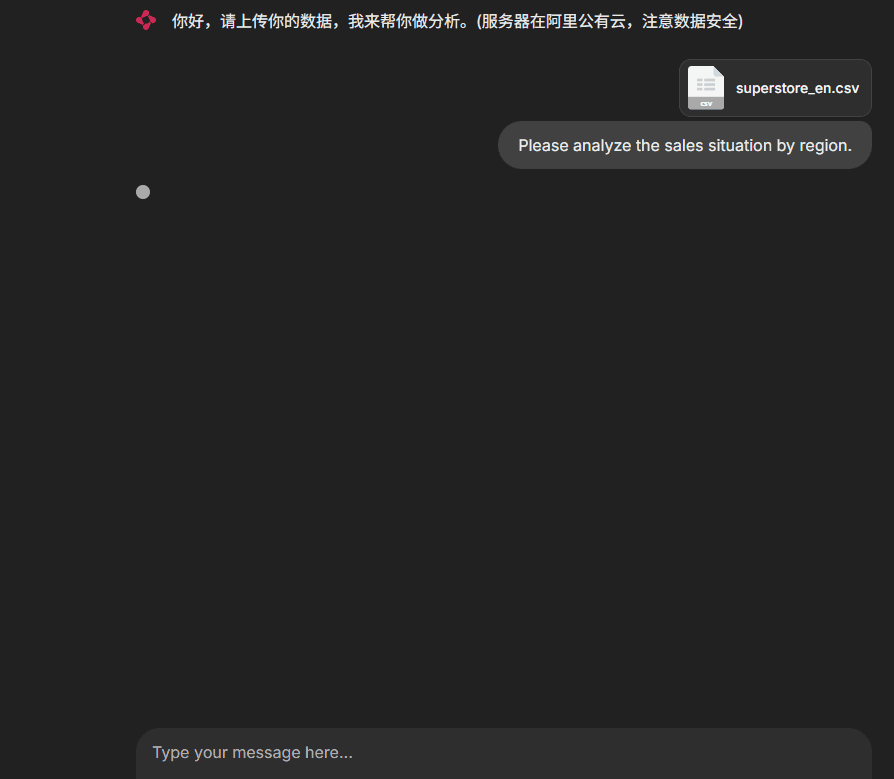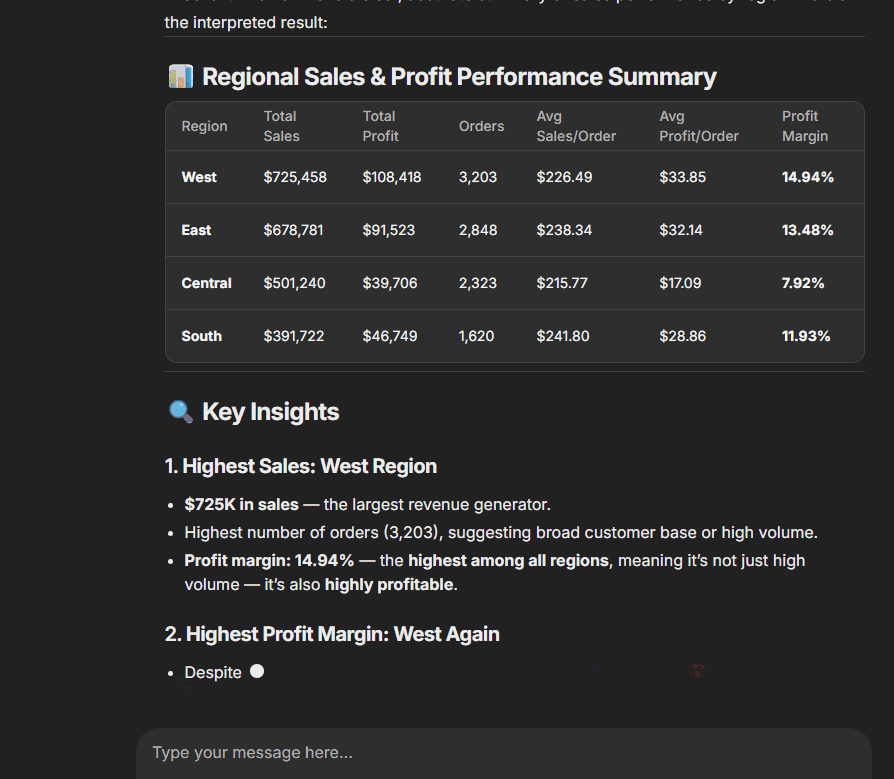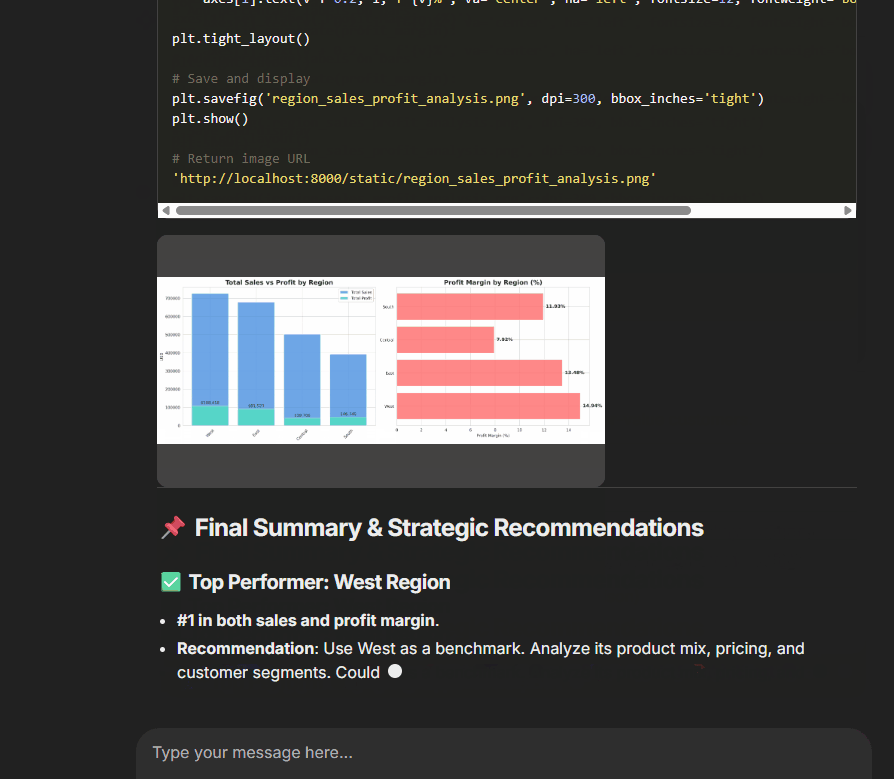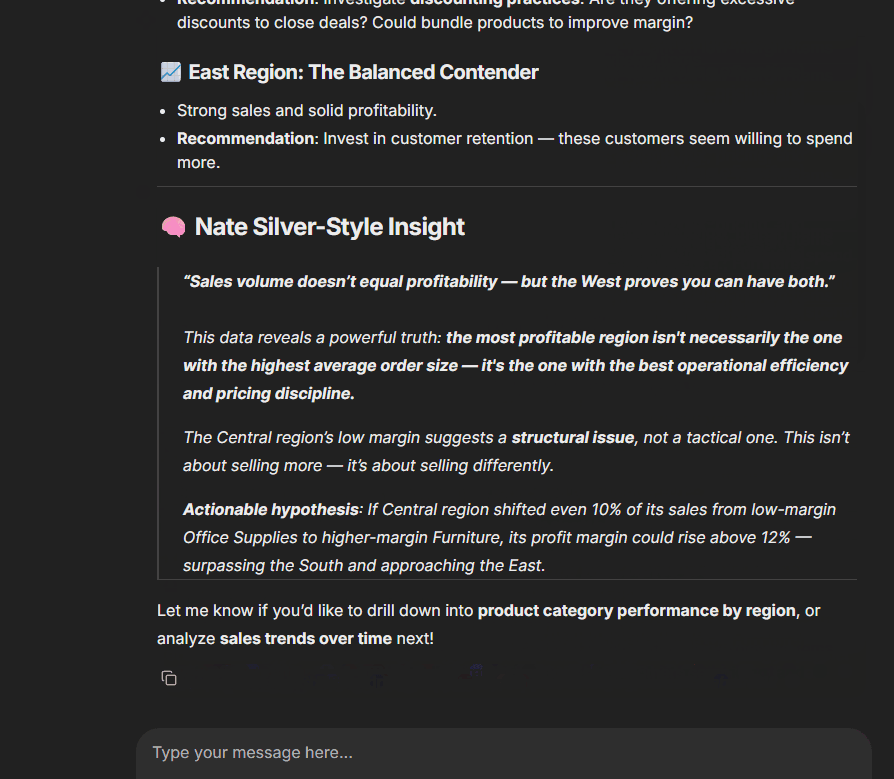
After all, this was just a single-agent app. It wasn’t that hard to build. If you remember, I explained how I used a ReAct agent to solve the Advent of Code challenges. Here’s that tutorial:

If you tweak that agent’s prompt a bit, you can get the same kind of data analysis ability I’m talking about.
Why Do I Call It a Failure?
Because my agent, like most that AI hobbyists build, is just one of those:
Perfect for impressing your boss with a beautiful, powerful prototype, but once real users try it, it suddenly breaks down and becomes industrial trash.
Why Do I Say That?
My agent has two serious problems.
1. Very poor robustness
This is the top feedback I got after giving it to analyst users.
If you try it once, it looks amazing. It uses methods and technical skills beyond a regular analyst to give you a very professional argument. You’d think replacing humans with AI was the smartest move you've ever made.
But data analysis is about testing cause and effect over time. You must run the same analysis daily or weekly to see if the assistant’s advice actually works.
Even with the same question, the agent changes its hypotheses and analysis methods each run. It then gives different advice each time.
That’s what I mean by poor stability and consistency.
Imagine you ask it to use an RFM model to segment your users and give marketing suggestions. Before a campaign, it uses features A, B, C and makes five levels for each. After the campaign, it suddenly adds a derived metric D and now segments on A, B, C, D.
You couldn’t even run an A/B test properly.
2. It suffers from context position bias
If you’ve read my earlier posts, you know my Data Analyst agent runs code through a stateful Jupyter Kernel-based interpreter.

This lets the agent act like a human analyst, first making a hypothesis, running code in a Jupyter notebook to test it, and then coming up with a new hypothesis based on results — iterating over and over.
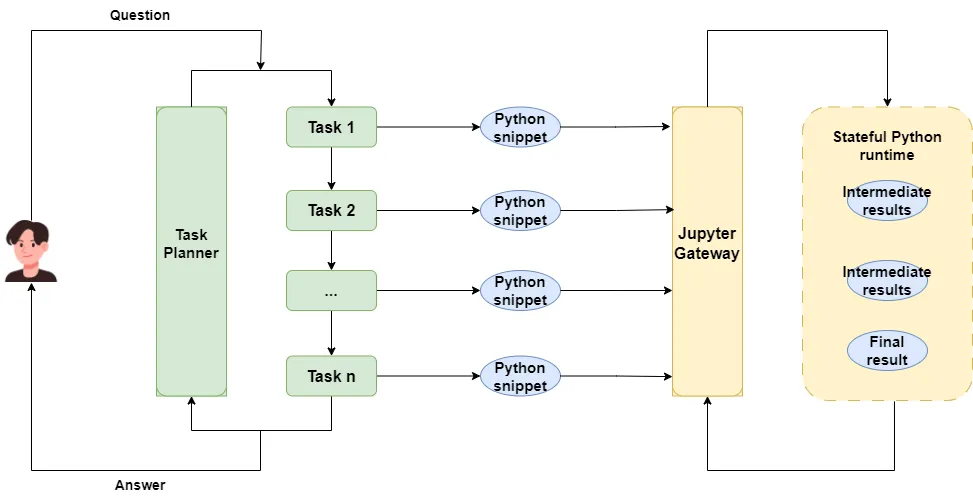
This gives the agent strong autonomous exploration and error-recovery skills.
But here’s the problem. In a past post, I mentioned that LLMs have position bias when dealing with long conversation histories:

In short, LLMs don’t treat each message fairly. They don’t weight importance by recency like you think they would.
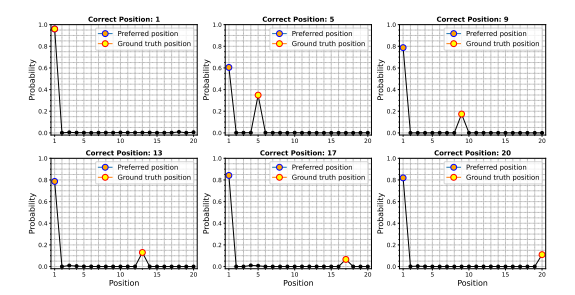
As we keep making and testing hypotheses, the history grows. Each message in it matters. The first shows the data structure, a later one proves a hypothesis wrong, so we skip it next time — all important.
The LLM doesn’t see it this way. As the process goes, it starts focusing on wrong messages while ignoring the ones that have been fixed. So it repeats mistakes.
This either wastes tokens and time or sends the analysis off-track into another topic. Neither is good.
So Phase One of my data analysis agent is done.
Any Ways to Fix It?
Build a multi-agent system with atomic skills
For robustness, you’d probably think of using a Context Engineer to lock in the plan and metric definitions before analysis starts.
Also, when an analysis works well, we should save the plan and prior assumptions in long-term memory.
Both mean giving the agent new skills.
But remember, my agent is based on ReAct, which means its prompt is already huge — over a thousand lines now.
Adding anything risks breaking this fragile system and disrupting prompt-following.
So a single agent won’t cut it. We should split the system into multiple agents with atomic skills, then use some orchestration to bring them together.
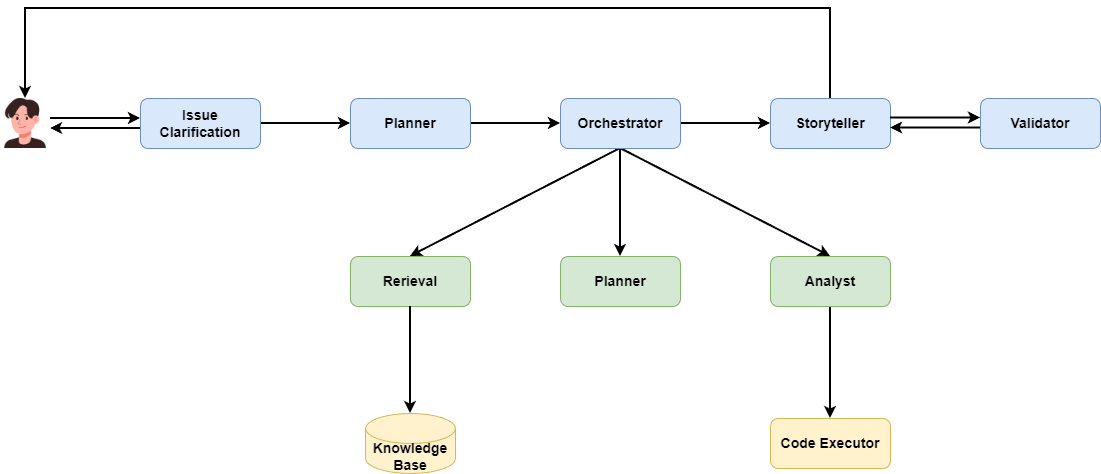
We can imagine this multi-agent app as a coordinate system with at least these agents:
- Issue Clarification Agent — asks the user questions to clarify the problem, confirm metrics, and scope.
- Retrieval Agent — pulls metric definitions and calculation methods from a knowledge base, plus analysis methods written by real data scientists.
- Planner Agent — proposes prior hypotheses, sets an analysis approach, and makes a full plan to keep later agents on track.
- Analyst Agent — breaks the plan into steps, uses Python to execute them, and tests the prior hypotheses.
- Storyteller Agent — turns complex technical results into engaging business stories and actionable advice for decision-makers.
- Validator Agent — ensures the whole process is correct, reliable, and business-compliant.
- Orchestrator Agent — manages all the agents and assigns tasks.
Choose the right agent framework
We need an agent framework that supports message passing. When a new task comes up or an agent finishes, a message should go to the orchestrator. The orchestrator should also send tasks by message.
The framework should support context state saving. Agents’ intermediate results should go to the context, not all to the LLM, so position bias doesn’t get in the way.
If you ask GPT, it will recommend LangGraph and Autogen.
I’d skip LangGraph. Even though its workflow is fine, its agents still run on LangChain, which I just don’t like.
When people compare Autogen with others, they say Autogen is better for research-heavy tasks like data analysis that need more autonomy.
But Autogen’s Selector Group Chat, while good for orchestrators, can’t manage message history well. You can’t control what goes to the LLM, and orchestration is a black box.
Autogen’s GraphFlow is also half-baked. Workflow only supports agent nodes and no context state management.

The bigger risk: Autogen has stopped development. For a 50k-star agent framework, that’s a shame.
What about Microsoft Agent Framework (MAF)?
I like it. Easy to use, takes good ideas from earlier frameworks, and avoids their mistakes.
I’m ready to use it with Qwen3 and DeepSeek:

I’m studying MAF’s Workflow feature now. It’s nice: multiple node types, context state management, OpenTelemetry observability, and orchestration modes like Switch-Case and Multi-Selection. It has almost everything I want.
It also feels ambitious. With new abilities like MCP, A2A, AG-UI, and Microsoft backing it, MAF should have a better long-term future than Autogen.
My Next Steps
I’m reading MAF’s user guide and source now. I’ll start using it in my agent system.
I’m still working on Deep Data Analyst. After switching frameworks, I’ll need to adapt things for a while.
The good news: a multi-agent system lets me add skills step by step, so I can share and show progress anytime instead of waiting until the whole project is done. 😂
I also want to explore Workflow’s potential in MAF. I’ll see if it can handle different AI agent design patterns. That will help us understand how to use this promising framework.
What are you interested in? Leave me a comment.
Don’t forget to subscribe to my newsletter <Mr.Q’s Weekend Notes> to get my latest agent research in your inbox without waiting.
And share my blog with your friends — maybe it can help more people.



