
Implement a Cache Decorator with Time to Live Feature in Python
A decorator based on @functools.lru_cache supports cache expiration


The Problem
The lru_cache decorator in Python’s functools package provides an implementation based on an LRU cache. Using this decorator functions with the same arguments will be significantly faster from the second time they are executed.
However, lru_cache cannot support cache expiration. If you want the cache to expire after a certain amount of time to update the cache when the function is called next time, lru_cache cannot achieve this.
How to Solve
1. Implement a lru_cache with a TTL feature
Therefore, I have implemented a new decorator based on lru_cache. This decorator can accept a ttl parameter. This parameter can accept a time in seconds, and when this time expires, the next function call will return a new value and refresh the cache.
For those who need to solve the problem urgently, here is the source code:
from functools import lru_cache, update_wrapper
from typing import Callable, Any
from math import floor
import time
def ttl_cache(maxsize: int = 128, typed: bool = False, ttl: int = -1):
if ttl <= 0:
ttl = 65536
hash_gen = _ttl_hash_gen(ttl)
def wrapper(func: Callable) -> Callable:
@lru_cache(maxsize, typed)
def ttl_func(ttl_hash, *args, **kwargs):
return func(*args, **kwargs)
def wrapped(*args, **kwargs) -> Any:
th = next(hash_gen)
return ttl_func(th, *args, **kwargs)
return update_wrapper(wrapped, func)
return wrapper
def _ttl_hash_gen(seconds: int):
start_time = time.time()
while True:
yield floor((time.time() - start_time) / seconds)The usage is very simple, like this:
@ttl_cache(maxsize=128, ttl=40)
def total_count(n):
result = 0
for _ in range(n):
result += n
return result2. Test the effectiveness
if __name__ == "__main__":
start = time.perf_counter()
for i in range(10):
time.sleep(6)
start = time.perf_counter()
print(f"round {i} got {total_count(65736222)} for {time.perf_counter() - start:.2f} seconds.")
end = time.perf_counter()
print(f"program runs at {end - start:.2f} seconds")We use a ttl_cache with an expiration time of 40 seconds. Then let the function be executed for 10 rounds, each round for 6 seconds.
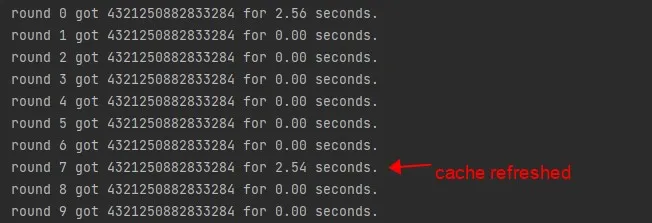
As we can see, when it reaches the 7th round, 6*7=42 (seconds). The cache is refreshed, indicating that our ttl_cache is successful, hurray.
Some Background Knowledge
1. What is LRU cache?
Assuming that the size of the cache is fixed, if the cache is full, some content needs to be deleted to make room for new content. But the question is, which content should be deleted? We certainly hope to delete those caches that are not useful and continue to leave useful data in the cache for later use. So, what data do we consider “useful” data?
The LRU cache strategy believes that the data that has been used recently should be “useful”, and the data that has not been used for a long time should be useless. When the capacity is full, those useless data should be deleted first.
2. How is the LRU cache implemented?
When implementing LRU, we need to focus on its read-and-write performance.
At this point, it is easy to think of using HashMap, which can achieve O(1) speed by accessing data according to the key. But the speed of updating the cache cannot reach O(1) because it needs to determine which data has been accessed the earliest, which requires traversing all the cache to find it.
Therefore, we need a data structure that both sorts by access time and can be randomly accessed in constant time.
This can be achieved by using HashMap+Doubly linked list. HashMap guarantees O(1) access time for data accessed through the key, and the doubly linked list passes through each data in the order of access time. The reason for choosing a doubly linked list instead of a singly linked list is that it can modify the linked list structure from any node in the middle, without having to traverse from the head node.
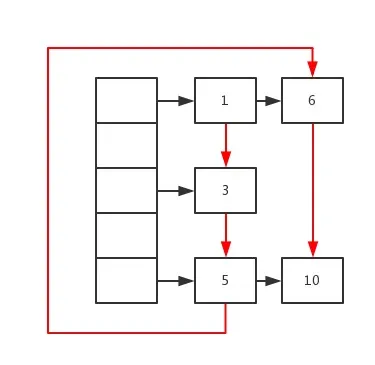
As shown in the figure below, the black part is the structure of HashMap, and the red arrow is the forward connection of the doubly linked list. It can be seen clearly that the data access order is 1->3->5->6->10. We only need to change the connection order of the linked list after each access to achieve our goal.
3. How does this help us implement ttl_cache?
We know that the LRU algorithm uses HashMap to implement fast data reading, so we can change the parameter by changing the hash key after the expiration time to implement cache expiration.
Since the hash key of lru_cache is calculated based on all hashable parameters in the decorated function, we only need to add a ttl_hash parameter and change the value of this parameter after the expiration time.
Code Interpretation
1. A general decorator template
When starting to write a decorator, I will use a decorator template code, which can help me write a decorator more quickly. For example:
def ttl_cache(maxsize: int = 128, typed: bool = False, ttl: int = -1):
def wrapper(func: Callable) -> Callable:
def wrapped(*args, **kwargs) -> Any:
return func(*args, **kwargs)
return update_wrapper(wrapped, func)
return wrapper2. A lazy execution generator code
Next, we need to generate a hash key every time the function decorated by ttl_cache is called, and if it has not exceeded the expiration time, this hash key should remain unchanged. If it exceeds the expiration time, this hash key should be different from the previously generated one.
Therefore, I plan to subtract the time when the code starts running from the current time, and then divide the result by the ttl parameter. Finally, the remainder is used as this hash key.
Since I need to save time when the code starts running and only get the latest hash key when necessary, the best way I can think of is to use a generator function:
def _ttl_hash_gen(seconds: int):
start_time = time.time()
while True:
yield floor((time.time() - start_time) / seconds)In this way, I can use the next() function to get the latest hash key when needed.
3. Use lru_cache to decorate the original function
Next, we will use lru_cache to decorate the original function, and the new function needs to pass in a ttl_hash parameter to generate a new hash after the expiration time:
@lru_cache(maxsize, typed)
def ttl_func(ttl_hash, *args, **kwargs):
return func(*args, **kwargs)In the wrapped function, we get a new hash_key every time and return a function call with ttl_hash to achieve our goal.
4. Don’t forget to copy the properties of the original function
Finally, don’t forget to copy the module, name, doc, and other attributes of the original function into the newly generated function. The easiest way here is to use update_wrapper in the functools module:
return update_wrapper(wrapped, func)Conclusion
There are other solutions, such as expiringdict.
But these solutions change the way how we use lru_cache, after all, we just want to make lru_cache more powerful to use.
The ttl_cache implemented in this article is thread-safe and can be used in a multi-threaded environment.
I hope you can like my implementation of the TTL cache. And welcome everyone to comment and provide valuable suggestions for improvement. Thank you for reading.



