
Conquer Retries in Python Using Tenacity: An End-to-End Tutorial
Enhancing your Python projects with robust retry mechanisms and error-handling techniques


This article will discuss Tenacity’s basic usage and customization capabilities.
This instrumental Python library provides a retry mechanism. We will also explore Tenacity’s retry and exception-handling capabilities through a practical example.
Introduction
Imagine you’re managing hundreds of web services, some located overseas (with high latency) and others pretty old (and not very stable). How would you feel?
My colleague Wang is in such a predicament. He told me that he was pretty frustrated:
Every day, he needs to check the invocation status of these remote services, and he often encounters timeout issues or other anomalies. Troubleshooting is particularly challenging.
Moreover, much of the client-side code was written by his predecessors, making it challenging to perform substantial refactoring. So, the services have to continue running as they are.
It would be great if there was a way to automatically reconnect these remote calls after an exception occurs. With tears in his eyes, Wang looked at me.
I assured him it was no problem and introduced him to a new tool from my toolbox: Tenacity. With just one decorator, the existing code can gain retry capabilities. Let’s see how to use it.
Installation and Basic Usage
Since Tenacity’s official website only offers a simple API document, let’s start with the library’s installation and some basic usage.
Installation
If you’re using pip, simply run the following:
python -m pip install tenacityIf you’re using Anaconda, Tenacity is not in the default channel, so you need to install it from conda-forge:
conda install -c conda-forge tenacityBasic usage
After installing Tenacity, let’s look at some basic usage of the library.
Simply add an @retry decorator and your code will have retry capabilities:
@retry()
async def coro_func():
passIf you want your code to stop retrying after a certain number of attempts, you can write it like this:
@retry(stop=stop_after_attempt(5))
async def coro_func():
passOf course, to avoid frequent retries that may exhaust connection pools, I recommend adding a waiting time before each retry. For example, if you want to wait for 2 seconds before each connection:
@retry(wait=wait_fixed(2))
async def coro_func():
passAlthough it’s not mentioned in the documentation, I prefer to wait an extra second longer than the last time before each retry to minimize resource waste:
@retry(wait=wait_incrementing(start=1, increment=1, max=5))
async def coro_func():
passFinally, if the retry is caused by an exception being thrown in the method, it is best to throw the exception back out. This allows for more flexible exception handling when calling the method:
@retry(reraise=True, stop=stop_after_attempt(3))
async def coro_func():
passAdvanced Features: Custom Callbacks
In addition to some common use cases, you may add your own retry determination logic, such as deciding based on the result of the method execution or printing the method invocation parameters before execution.
In this case, we can use Custom Callbacks for customization.
There are two ways to extend Custom Callbacks:
One is the recommended approach from the documentation: writing an extension method.
This method will be passed a RetryCallState instance as a parameter when executed.
Through this parameter, we can obtain the wrapped method, the parameters of the method call, the returned result, and any thrown exceptions.
For example, we can use this approach to judge the return value of a method and retry if the value is even:
from tenacity import *
def check_is_even(retry_state: RetryCallState):
if retry_state.outcome.exception():
return True
return retry_state.outcome.result() % 2 == 0Of course, before making this judgment, if an exception is thrown, retry directly.
If you need to pass additional parameters in the extension method, you can add a wrapper outside the extension method.
For example, this wrapper will pass a logger parameter. When the number of retries exceeds two, it will print the retry time, method name, and method parameters to the log:
def my_before_log(logger: Logger):
def my_log(retry_state: RetryCallState):
fn = retry_state.fn
args = retry_state.args
attempt = retry_state.attempt_number
if attempt > 2:
logger.warning(f"Start retry method {fn.__name__} with args: {args}")
return my_logReal-World Network Example
Finally, to give you a deep impression of using Tenacity in your projects, I will use a remote client project as an example to demonstrate how to integrate Tenacity’s powerful capabilities.
This project will simulate accessing an HTTP service and deciding whether or not to retry based on the returned status code.
Of course, to avoid wasting server resources due to long connection wait times, I will also add a 2-second timeout for each request. If a timeout occurs, the connection will be retried.
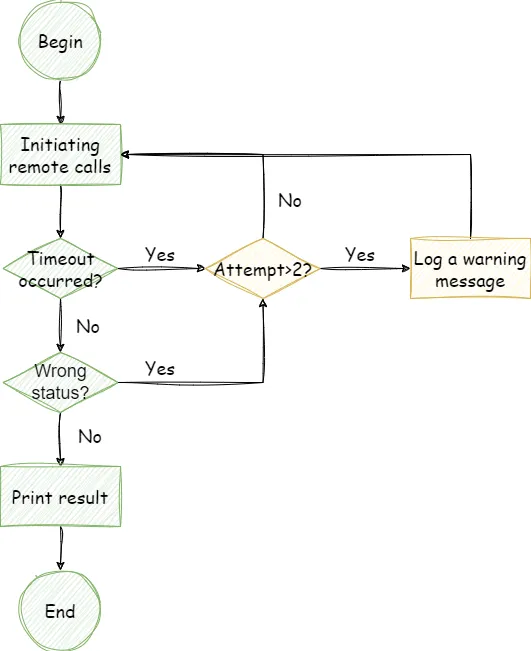
Before starting the code, I will implement several extension methods. One of the methods is to judge when a method’s retry count exceeds two, and print a warning message in the log:
import asyncio
import logging
import random
import sys
import aiohttp
from aiohttp import ClientTimeout, ClientSession
from tenacity import *
def ready_logger(stream, level) -> logging.Logger:
logger = logging.getLogger(__name__)
logger.setLevel(level)
handler = logging.StreamHandler(stream)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
logger = ready_logger(stream=sys.stderr, level=logging.DEBUG)
def my_before_log(logger: logging.Logger):
def log_it(retry_state: RetryCallState):
fn = retry_state.fn
attempt = retry_state.attempt_number
if attempt > 2:
logger.warning(f"Retrying method {fn.__name__} at the {attempt} attempt")
return log_itAnother extension method is to judge the returned status code. If the status code is greater than 300, retry. Of course, timeouts will also trigger retries.
def check_status(retry_state: RetryCallState) -> bool:
outcome: Future = retry_state.outcome
if outcome.exception():
return True
return outcome.result() > 300Next, we have the implementation of the remote call method. After writing the method, remember to add Tenacity’s retry decorator. The strategy I use here is to retry up to 20 times, waiting for 1 second longer than the previous retry before each retry.
Of course, don’t forget to add the two extension methods we just implemented:
@retry(stop=stop_after_attempt(20),
wait=wait_incrementing(start=1, increment=1, max=5),
before=my_before_log(logger),
retry=check_status)
async def get_status(url_template: str, session: ClientSession) -> int:
status_list = [200, 300, 400, 500]
url = url_template.format(codes=random.choice(status_list))
print(f"Begin to get status from {url}")
async with session.get(url) as response:
return response.status
async def main():
timeout: ClientTimeout = aiohttp.ClientTimeout(2)
async with aiohttp.ClientSession(timeout=timeout) as session:
tasks = [asyncio.create_task(
get_status('https://httpbin.org/status/{codes}', session)) for _ in range(5)]
result = await asyncio.gather(*tasks)
print(result)
if __name__ == "__main__":
asyncio.run(main())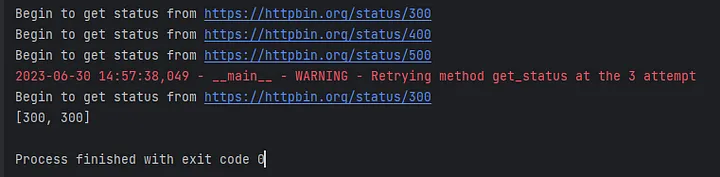
Mission complete! Wasn’t that super simple?
Conclusion
I’m glad I helped Wang solve another problem.
By using Tenacity, we can easily equip existing code with various retry mechanisms, thereby enhancing the robustness and self-recovery capabilities of the program.
I would be even happier if this library could help you solve problems. Feel free to leave a comment and discuss.



